1. Overview — 为什么是 agent-first
我们要解决的问题
材料计算社区有两类工具:
- VESTA / Materials Studio / pymatgen Python API — 给人用,需要鼠标点或长 Python 脚本,agent 不好驱动。
- 传统命令行(VASP / Quantum ESPRESSO / ASE-CLI) — 命令分散、参数复杂、输出动辄上千行、没有"会话状态",agent 跑两步就丢失上下文。
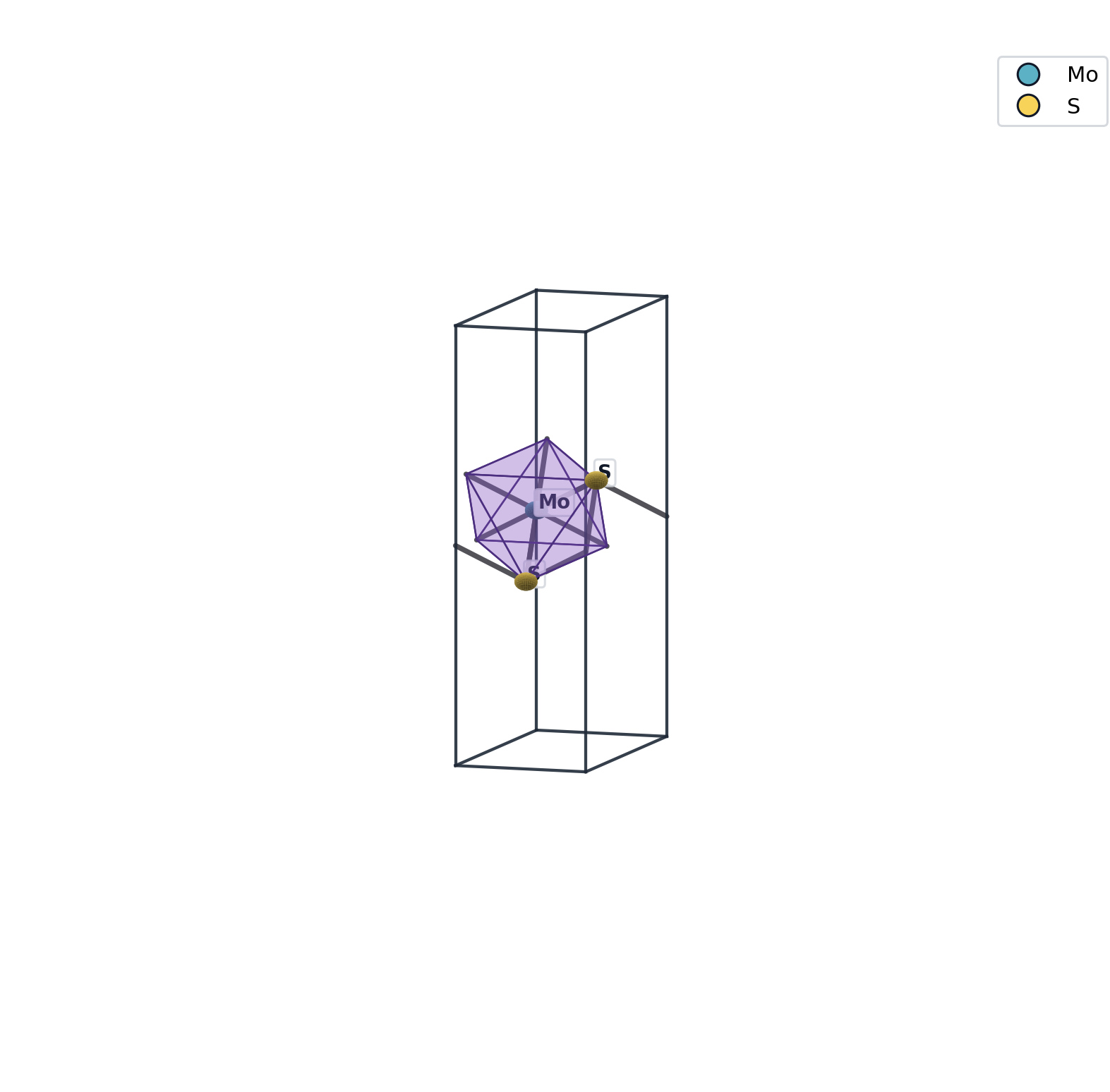
mat 想填的位置是:让一个 LLM agent 用 3–4 个 token 就能跑通 "造结构 → 看 motif → 改晶格 → 出 DFT 输入" 全流程,并且每一步都能"看图自检"。
三条设计原则
原则 1:command 层与 resource 层分离
借鉴 GitHub gh:
- command 表达高层用户意图,不容易自然 resource 化的就放这里:
gh login/mat init/mat build/mat strain/mat reproduce。 - resource 用 RESTful 路径 + 5 个动词覆盖长尾能力:
mat /motifs list、mat /lattice update、mat /sites create。
这样 agent 只需要学 5 个动词(list / get / create / update / delete),就能 cover 所有长尾——再加上 mat <command> 处理高频意图,新增功能不会让命令爆炸。
原则 2:默认输出语义化,结构化按需取
| 模式 | 何时用 | 例子 |
|---|---|---|
| 默认(人类可读) | agent 读取并理解 | mat motifs → 1 motif(s) ... MoS6_octahedral ... cn=6 ... |
--json | 程序串联 | mat motifs --json → 完整 JSON |
--json --jq EXPR | agent context 裁剪 | --jq '.[].label' → 只留 motif 名 |
-q | shell 管道 | mat build mos2 -q → 只打印输出文件名 |
要点:--jq 在数据进入 LLM context 之前裁剪,节省 token + 避免无关字段污染推理。
原则 3:所有 side-effect 自动落盘 + 自动可视化
每个会写结构的命令完成后,自动产出三联:
mos2.vasp ← 给下游 DFT
mos2.png ← 给多模态 agent / 人 自检
mos2.summary.md ← 给文本 agent / 复现日志PNG 长这样:
多模态 agent 直接读图就能判断"我建出来的 MoS2 八面体对不对",不需要再写一段 Python 复检。
与其他工具的对比
| mat | pymatgen | ASE | VESTA | |
|---|---|---|---|---|
| 给谁用 | agent + 人 | 程序员 | 程序员 | 人(GUI) |
| 调用粒度 | 1 token = 1 步 | API 调用 | API 调用 | 鼠标点 |
| 配位 motif 抽象 | 一等公民 | 间接(CrystalNN) | 间接(NeighborList) | 仅可视化 |
| 自动出图 | 每步都出 | 否 | 否 | 手动 |
| 上下文记忆 | 隐式 context | 否 | 否 | 否 |
| 论文复现 recipe | 是 | 否 | 否 | 否 |
适用范围
- 2D 材料(TMD / 石墨烯类 / hBN / 群 V 单层 ...)
- 异质双层 / 界面 / 错位(moiré)
- 表面 + 吸附(slab + adsorbate)
- 点缺陷(vacancy / substitute / displace)
- 上接 VASP DFT 输入
不在范围:复杂键能/能带后处理(用 pymatgen、VASPKIT);流体/分子 MD(用 ASE/LAMMPS)。